Intro
In the previous part of the series, we set up an API to get predictions from GPT-3 programmatically. In this part, we will estimate the confidence of the predictions, and evaluate the accuracy of GPT-3 labelling.
Confidence – or is it?
Last time we finished with binary predictions – TRUE or FALSE. But we can do better. We can gauge the confidence of the predictions. This confidence can be used in a variety of ways, for example, you might want to discard low-confidence predictions, or label them manually later.
Let’s look at an example.
It is easiest to see it in the GPT-3 GUI. Set “Temperature” to 0, and “Show probabilities” to “Full spectrum”. Now insert our prompt from the previous part:
# List of games
name: DOOM
description: Now includes all three premium DLC packs (Unto the Evil, Hell Followed, and Bloodfall), maps, modes, and weapons, as well as all feature updates including Arcade Mode, Photo Mode, and the latest Update 6.66, which brings further multiplayer improvements as well as revamps multiplayer progression.
name: This War of Mine
description: In This War Of Mine you do not play as an elite soldier, rather a group of civilians trying to survive in a besieged city; struggling with lack of food, medicine and constant danger from snipers and hostile scavengers. The game provides an experience of war seen from an entirely new angle.
name: Divinity: Original Sin 2 - Definitive Edition
description: The eagerly anticipated sequel to the award-winning RPG. Gather your party. Master deep, tactical combat. Join up to 3 other players - but know that only one of you will have the chance to become a God.
name: Portal
description: Portal™ is a new single player game from Valve. Set in the mysterious Aperture Science Laboratories, Portal has been called one of the most innovative new games on the horizon and will offer gamers hours of unique gameplay.
name: AdVenture Capitalist
description: Welcome, eager young investor, to AdVenture Capitalist! Arguably the world's greatest Capitalism simulator!
# Table of games and their genres (TRUE or FALSE)
| name | genre_action | genre_rpg | genre_strategy | genre_simulation | genre_puzzle | genre_casual | genre_adventure | genre_platformer |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
And request completion. You should see something like this:

This is similar to what we’ve seen before, however, note that the text has slightly different colours. The colour corresponds to the probability of that token. If you click on one of the words in the completion, you see the following:
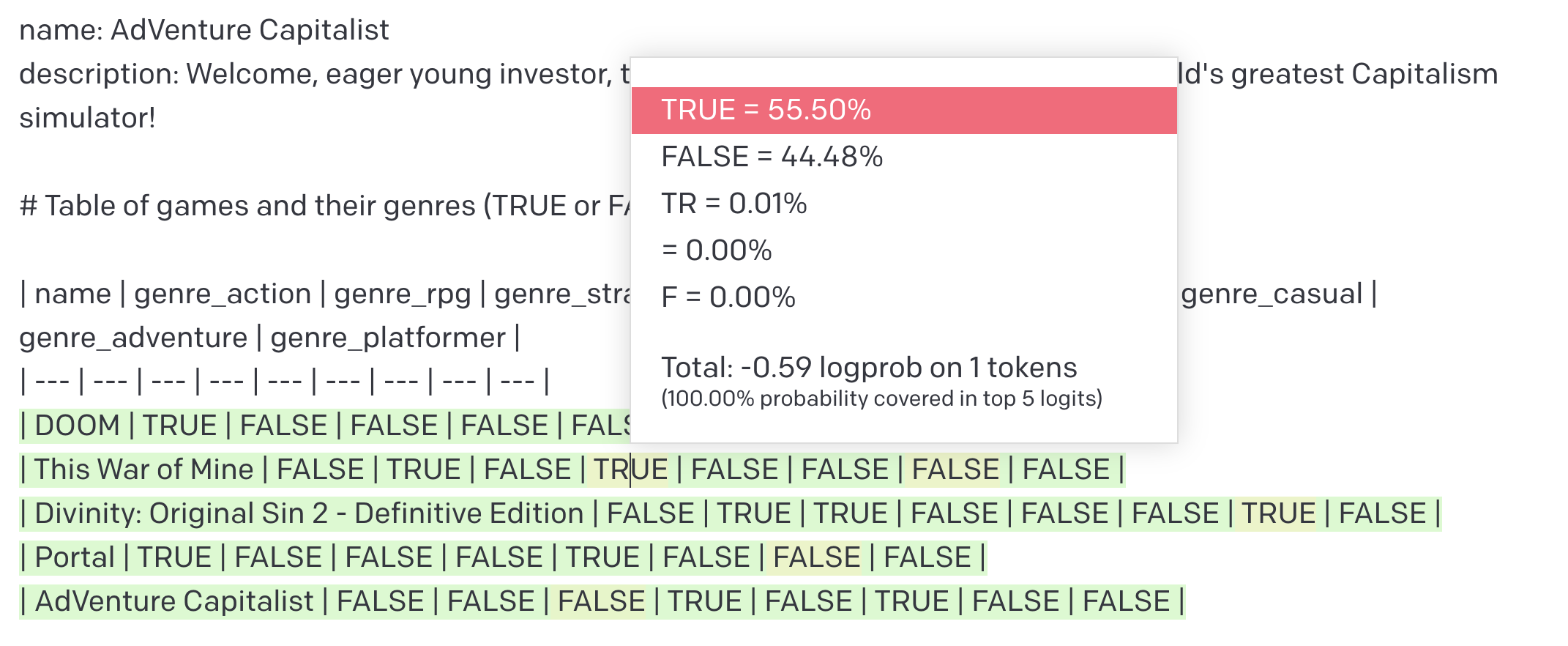
You see the probability of the produced token (TRUE = 55.50%) and the next 4 most probable tokens (FALSE = 44.48%, TR = 0.01%, etc.). This particular token is associated with low confidence, as the probabilities of TRUE and FALSE are quite close1.
An API call with token probabilities
When we use the API, GPT-3 does not return the token probability directly, as seen in the GUI. Instead, we have access to logprobs – logarithm of the probability of the token (documentation). GPT-3 can only return the log probabilities of the chosen token + top 5 most likely other tokens2.
Let’s modify our API call to include "logprobs": 5 in the params:
params = {
"prompt": """# List of games
name: DOOM
description: Now includes all three premium DLC packs (Unto the Evil, Hell Followed, and Bloodfall), maps, modes, and weapons, as well as all feature updates including Arcade Mode, Photo Mode, and the latest Update 6.66, which brings further multiplayer improvements as well as revamps multiplayer progression.
name: This War of Mine
description: In This War Of Mine you do not play as an elite soldier, rather a group of civilians trying to survive in a besieged city; struggling with lack of food, medicine and constant danger from snipers and hostile scavengers. The game provides an experience of war seen from an entirely new angle.
name: Divinity: Original Sin 2 - Definitive Edition
description: The eagerly anticipated sequel to the award-winning RPG. Gather your party. Master deep, tactical combat. Join up to 3 other players - but know that only one of you will have the chance to become a God.
name: Portal
description: Portal™ is a new single player game from Valve. Set in the mysterious Aperture Science Laboratories, Portal has been called one of the most innovative new games on the horizon and will offer gamers hours of unique gameplay.
name: AdVenture Capitalist
description: Welcome, eager young investor, to AdVenture Capitalist! Arguably the world's greatest Capitalism simulator!
# Table of games and their genres (TRUE or FALSE)
| name | genre_action | genre_rpg | genre_strategy | genre_simulation | genre_puzzle | genre_casual | genre_adventure | genre_platformer |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |""",
"engine": "text-davinci-002",
"max_tokens": 200,
"temperature": 0,
"logprobs": 5,
}
response = openai.Completion.create(**params)
response = response.to_dict_recursive()
Looking at the response, we will see some new data. response["choices"][0]["logprobs"] has the following content:
'logprobs': {
'tokens': [
'\n',
'|',
' DO',
'OM',
' |',
' TRUE',
' |',
' FALSE',
...
'token_logprobs': [
-0.05465243,
-0.0013697118,
-0.030774955,
-5.460492e-07,
-0.036972597,
-0.030116804,
-0.0160796,
-0.005509305,
...
'top_logprobs': [{
' ---': -8.317702,
'\n': -0.05465243,
' ': -2.9530916,
' ': -7.5652566,
' ': -9.768109},
{'DO': -7.1756744,
'\n': -9.548737,
'D': -8.082862,
'|': -0.0013697118,
' |': -9.038816},
...
tokens are the returned tokens3 and token_logprobs are their corresponding log probabilities. We can very easily translate these log probabilities into actual probabilities by exponentiation: e.g. let’s take the probability of the TRUE token: $$e^{-0.030116804} = 0.97033218824$$
So the probability of seeing a TRUE token in this position, according to GPT-3 is ~0.97.
top_logprobs are the next 5 most likely tokens and their log probabilities. We will not be using these here.
Parsing token probabilities
Now that we have the probabilities available to us, all we need to do is to parse the response to create a table of probabilities of the game, for each label. Here I have written the code to parse the responses into pandas.DataFrame. It is not the most efficient, but it does the job.
import numpy as np
import pandas as pd
def yield_elements_cycle(iterable, limit=100000):
"""Yield elements of an iterable in a cycle. limit is the maximum number of
elements to yield."""
for i in range(limit):
yield iterable[i % len(iterable)]
return "Limit reached"
def parse_response(response):
columns = "genre_action | genre_rpg | genre_strategy | genre_simulation | genre_puzzle | genre_casual | genre_adventure | genre_platformer".split(
" | "
)
tokens = response["choices"][0]["logprobs"]["tokens"]
probs = response["choices"][0]["logprobs"]["token_logprobs"]
column = yield_elements_cycle(columns)
data = iter(response.get("data", []))
res = []
for i, t in enumerate(tokens):
t = t.strip(" ")
if "<|endoftext|>" in t:
break
elif t == "\n":
d = {"name": "".join(tokens[i:]).split('|')[1].strip()}
res.append(d)
elif t == "TRUE":
p = np.exp(probs[i])
d.update({next(column): p})
elif t == "FALSE":
p = 1 - np.exp(probs[i])
d.update({next(column): p})
df = pd.DataFrame(res)
return df
parse_response(response):

Putting it all together
Let’s put everything together to obtain a labelled dataset.
import json
import pandas as pd
import numpy as np
from sklearn.metrics import RocCurveDisplay
import matplotlib.pyplot as plt
import openai
# insert your OpenAI api-key, to be found here: https://beta.openai.com/account/api-keys
openai.api_key = "sk-..."
### LOAD AND PREPROCESS DATA ###
# load data (source https://www.kaggle.com/datasets/trolukovich/steam-games-complete-dataset)
df = pd.read_csv("steam_games.csv")
# parse tags into boolean table of tags for each game
tags = (
pd.DataFrame([
{g: 1 for g in tags}
for tags in df["popular_tags"].fillna("").str.split(',').values])
.fillna(0)
.astype(bool)
)
# manually pick tags, we will use them as labels
tags_to_classify = [
"Action",
"RPG",
"Strategy",
"Simulation",
"Puzzle",
"Casual",
"Adventure",
"Platformer"
]
# extract number of reviews for each game, in order to later pick most reviewed games
n_reviews = df["all_reviews"].str.extract(r"(\([\d,]+\))")
n_reviews["n_reviews"] = n_reviews[0].str.strip("() ").str.replace(",", "").astype(float)
# put all data together
data = (
pd.concat([
df[["name", "desc_snippet"]],
tags[tags_to_classify],
n_reviews["n_reviews"]
], axis=1)
.dropna(subset=["n_reviews"])
.sort_values("n_reviews", ascending=False)
.reset_index(drop=True)
)
data.columns = data.columns.map(lambda x: x.lower())
# pick top 100 games as a benchmark dataset
data = data.iloc[:100]
data_records = data.to_dict(orient="records")
### GETTING COMPLETION FROM GPT-3 ###
def make_prompt(name_descr_records):
def make_game_string(name_descr_record):
return "\n".join([
f"name: {name_descr_record['name']}",
f"description: {name_descr_record['desc_snippet']}"
])
def make_all_games_strings(name_descr_records):
return "\n\n".join(make_game_string(rec) for rec in name_descr_records)
return f"""# List of games
{make_all_games_strings(name_descr_records)}
# Table of games and their genres (TRUE or FALSE)
| name | genre_action | genre_rpg | genre_strategy | genre_simulation | genre_puzzle | genre_casual | genre_adventure | genre_platformer |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |"""
N_GAMES_IN_PROMPT = 5
responses = []
# obtain GPT-3 labels; note that this part will use your GPT-3 credit, though very little of it: with prices of January 2023 it costed me ~0.1 USD.
ixs = np.arange(0, len(data_records) + N_GAMES_IN_PROMPT, N_GAMES_IN_PROMPT)
for start, stop in list(zip(ixs[:-1], ixs[1:])):
print(stop, end=", ")
params = {
"prompt": make_prompt(data_records[start:stop]),
"engine": "text-davinci-003",
"max_tokens": 200,
"temperature": 0,
"logprobs": 5,
}
response = openai.Completion.create(**params)
response = response.to_dict_recursive()
response["data"] = {
"game_names": [d["name"] for d in data_records[start:stop]]
}
responses.append(response)
# store responses for later use, to avoid requesting completion one more time
with open("responses.json", "w") as f:
json.dump(responses, f)
# uncomment this to load the responses
# with open("responses.json", "r") as f:
# responses = json.load(f)
### PARSING RESPONSES ###
def yield_elements_cycle(iterable, limit=100000):
"""Yield elements of an iterable in a cycle. limit is the maximum number of
elements to yield."""
for i in range(limit):
yield iterable[i % len(iterable)]
return "Limit reached"
def parse_response(response):
columns = "genre_action | genre_rpg | genre_strategy | genre_simulation | genre_puzzle | genre_casual | genre_adventure | genre_platformer".split(
" | "
)
tokens = response["choices"][0]["logprobs"]["tokens"]
probs = response["choices"][0]["logprobs"]["token_logprobs"]
column = yield_elements_cycle(columns)
data = iter(response.get("data", []))
res = []
for i, t in enumerate(tokens):
t = t.strip(" ")
if "<|endoftext|>" in t:
break
elif t == "\n":
d = {"name": "".join(tokens[i:]).split('|')[1].strip()}
res.append(d)
elif t == "TRUE":
p = np.exp(probs[i])
d.update({next(column): p})
elif t == "FALSE":
p = 1 - np.exp(probs[i])
d.update({next(column): p})
df = pd.DataFrame(res)
return df
data_gpt = pd.concat([parse_response(r) for r in responses]).reset_index(drop=True)
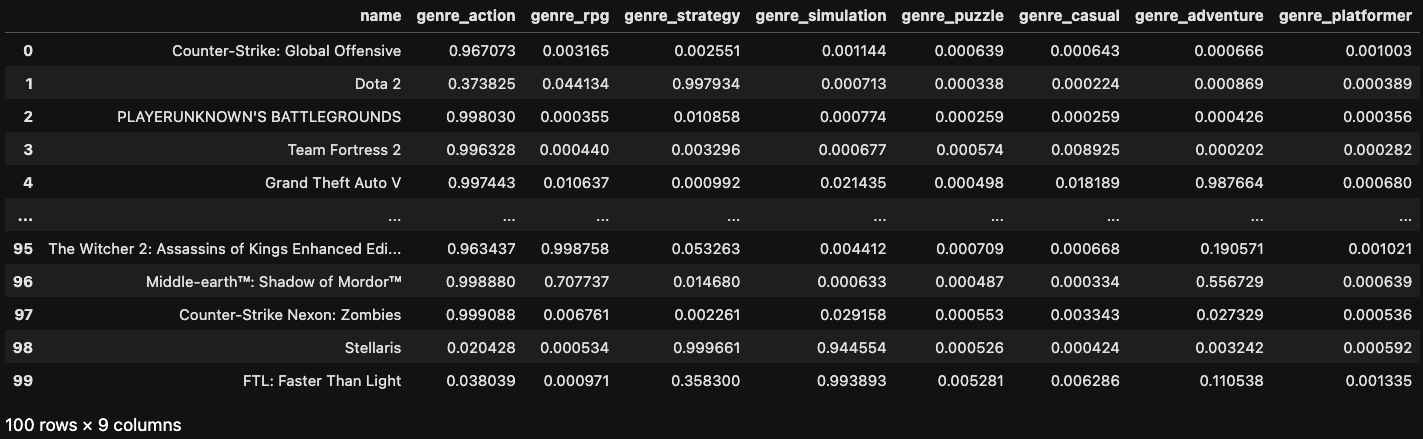
data_gpt:
Evaluation
Now it is time to evaluate the results of our predictions. In real projects, you want to label new data, and here you would create a benchmark dataset with a manually labelled subset of data, and test GPT-3 classification against it. But here we will test GPT-3 labels against those available in the original dataset.
We will use ROC AUC for each label as a measure of how well GPT-3 labels the data.
ax = plt.figure(dpi=100).add_subplot(1,1,1)
labels = data_gpt.drop(columns=['name']).columns.tolist()
for label in labels:
y_true = data[label.split("_")[1]].astype(float)
y_pred = data_gpt[label]
RocCurveDisplay.from_predictions(y_true, y_pred, name=label, ax=ax)
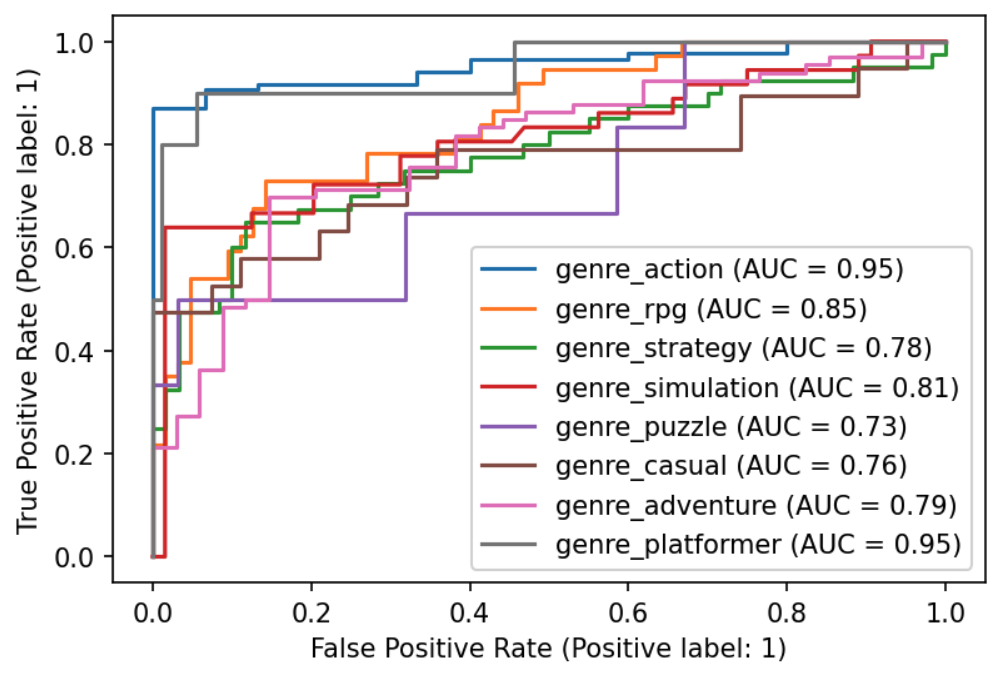
As we can see, for all labels, GPT-3 performs above the chance level. It performed best for Action and Platformer, and worst for Puzzle.
Conclusions
I have walked you through an approach for zero-shot multilabel classification using GPT-3. I find it suitable for a variety of scenarios where I need to label some unspecialized text data quickly for a first rough stab at modelling. Generally, with some tweaking of the prompt, it produces results at a level of an untrained human labeller for a fraction of the cost and time. The example use case I provided in this series of posts – predicting the genre of the game by name and short description – is one of the worst results I have gotten with this approach, and it is still quite reasonable.
I hope you found this useful and don’t hesitate to prompt me for more information in the comments.
Note that the probabilities of other tokens besides TRUE and FALSE are extremely low. This is good – it means that GPT-3 “understands” the format in which it should be producing the response, and not trying to insert tokens other than TRUE or FALSE here. This is exactly what we want to see to get a consistent response which can be parsed programmatically. ↩︎
OpenAI state that they can approve you getting more than 5
logprobs for specific use cases, but you need to communicate the use case to them. ↩︎Note that the word “DOOM” consists of 2 tokens. It is expected that tokens do not correspond exactly to words. It is just how the tokenizer in GPT-3 works. ↩︎